I just searched for the thing in the title but unfortunately the best result I got was worked on floats, not bytes, so I decided to make my own.

The problem
A transformation function that inputs a 8bit image and converts it to a same-sized 32bit RGBA image with the following components: R=GX, G=GY, B=Grayscale, A=0. Where GX and GY is the outputs of the 3×3 (1,2,1) Sobel Operator.
More info on Wikipedia: https://en.wikipedia.org/wiki/Sobel_operator
Where to start
The Sobel operator is using 2 convolution filters: The vertical one is [[1,2,1],[0,0,0],[-1,-2,-1]]. If we transpone this matrix we get the horizontal filter: [[1,0,-1],[2,0,-1],[1,0,-1]].
One fundamental operation is convolving the input grayscale values with a 3×1 matrix: [1,2,1]. (Later we can reuse this for the convolution with the negative [-1,-2,-1] matrix, we just have to flip the sign.) In Dlang, this [1,2,1] filter would look like:
for each rows: foreach(i; 1..15) dst[i] = (src[i-1] + 2*src[i] + src[i+1])>>2;

Left: original grayscale image. Right: (original * [1,2,1]) >> 2. It’s like a horizontal smoothing filter.
Translate a+2b+c>>2 to SSE
(Note that how wonderful is the C precedence order, that I spared the parentheses here. NOT :D)
Because there are 2 sums and 2 shr1’s, the PAVGB instruction is perfect for the job:
avg(avg(a, c), b)
To process a full 16×16 pixel block, I will use a 3 element circular buffer for each row. After I got 3 rows in that buffer, I will be able to calculate the vertical GX component of the Sobel Operator. For GX I feel like it is not worth to bother with a circular buffer at all.
Here’s the code that maintains this circular of the [1,2,1] convolutions. XMM0..XMM2 is the curcular buffer.
Here’s the code that maintains this circular buffer of the [1,2,1] convolutions. It works on a 16×16 image region, and produces 14 rows.
void SSE_sobel121(ubyte* src, ubyte* dst, size_t stride){ asm{
mov RAX, src; mov RDI, dst;
pxor XMM8, XMM8; //const 0
pcmpeqb XMM9, XMM9; //const -1
movaps XMM0,XMM1; movaps XMM1,XMM2; movups XMM3,[RAX]; add RAX, stride; movaps XMM2,XMM3; movaps XMM4,XMM3; pslldq XMM2,1; psrldq XMM4,1; pavgb XMM2,XMM4; pavgb XMM2,XMM3;
movaps XMM0,XMM1; movaps XMM1,XMM2; movups XMM3,[RAX]; add RAX, stride; movaps XMM2,XMM3; movaps XMM4,XMM3; pslldq XMM2,1; psrldq XMM4,1; pavgb XMM2,XMM4; pavgb XMM2,XMM3;
mov R8, 14;
l1:
movaps XMM0,XMM1; movaps XMM1,XMM2; movups XMM3,[RAX]; add RAX, stride; movaps XMM2,XMM3; movaps XMM4,XMM3; pslldq XMM2,1; psrldq XMM4,1; pavgb XMM2,XMM4; pavgb XMM2,XMM3;
//here we have 3 GY rows in XMM0..XMM1
add RDI, stride; movups [RDI], XMM1; //output the middle row for testing
dec R8; jnz l1;
}}
It’s pretty ugly with the 3 repetitions, but I just found out that mixin() is just don’t work inside an asm{} block. But anyhow, we now have the top and the bottom part of the [[1,2,1],[0,0,0],[-1,-2,-1]] kernel at hand.
Get Sobel.GY from the circular buffer
In every row we add the [1,2,1] convolution on the top and subtract the bottom one. We also reduce the result by 1 bit to fit that -255..255 range into one byte (0..255).
So we’re about to calculate: (top-bottom)/2+128
Using the favourite PAVGB instruction: avg(top, 255-bottom)
The actual code which is generating GY from the circular XMM0..XMM2 buffer is:
movaps XMM3,XMM2; pxor XMM0, XMM9; pavgb XMM3,XMM0; //XMM3:GY XMM9:-1
Let’s calculate GX!
First we have to do the convolution with the vertical matrix [1,2,1], then we have to subtract the left side from the right side.
//XMM13..XMM15 is a buffer of the last 3 input rows movaps XMM4, XMM13; pavgb XMM4, XMM15; pavgb XMM4,XMM14; //XMM4: vertical convolution with [1,2,1] movaps XMM5, XMM4; pslldq XMM4,1; psrldq XMM5,1; //XMM4, XMM5: left/right neighbors pxor XMM4, XMM9; pavgb XMM4,XMM5; //XMM4: GX XMM9:-1

Left: original; Middle: GY; Right: GX; (Actually it’s -GX and -GY so the lighting effect comes from the upper/left)
Combine the components into a dword
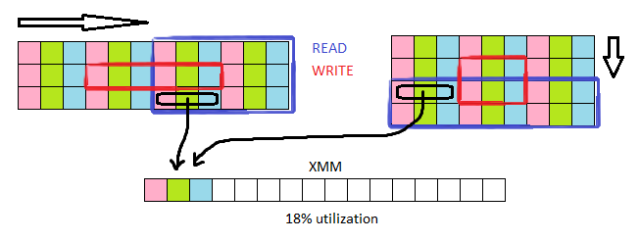
The targetet pixel format is 8bit RGBA(GX, GY, Luma, 0). It is used for further processing in my program.
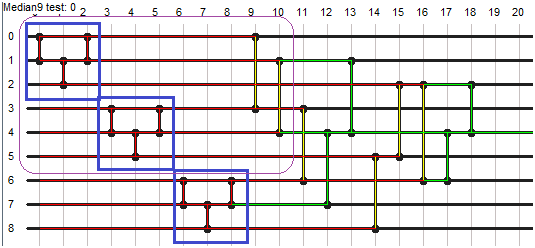
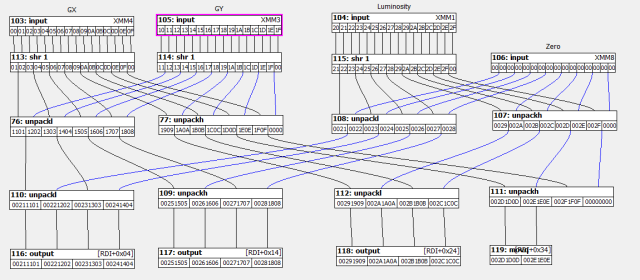
To make it from uchar[16] XMM registers we need to use the PUNPCK[L/H][BW/WD] instructions. I hate these instructions because I always mismatch them, also with the 2 operand model I always need to save values too. But with the aid of my little visual tool it was easy to design.
The output component interleaver.
This output stage is also ensures that only the inner 14 pixels are written, given by the 3×3 convolution window that works on 16 sse bytes.
//in: XMM4:GX, XMM3:GY, XMM14:Luma, XMM8:0 //out: RDI+0x4..RDI+0x3C, 14 DWords psrldq XMM4,1; psrldq XMM3,1; movaps XMM5,XMM14; psrldq XMM5,1; movaps XMM6,XMM4; punpcklbw XMM4,XMM3; movaps XMM7,XMM6; punpckhbw XMM6,XMM3; movaps XMM0,XMM5; punpcklbw XMM5,XMM8; punpckhbw XMM0,XMM8; movaps XMM10,XMM4; punpcklwd XMM4,XMM5; add RDI, RDX; punpckhwd XMM10,XMM5; movups [RDI+0x04],XMM4; movaps XMM5,XMM6; movups [RDI+0x14],XMM10; punpcklwd XMM6,XMM0; movups [RDI+0x24],XMM6; punpckhwd XMM5,XMM0; movq [RDI+0x34], XMM5;
The above code is not so human readable but it was generated from the preceding dataflow diagram.

From left to right: Original; GX; GY; (GX, GY); (0, 0, Luma); (GX, GY, Luma)
Extending the algorithm to the whole image
A lot of work is needed to upgrade the optimized algorithm to be able to work on real life data. In my opinion this is the most boring part of optimization. Sometimes I mix the unpoptimized version with the optimized one. But this time it makes more sense to use the faster optimized version everywhere with a bit of redundancy at the edges.
There are 3 areas of an image that need to be processed by differently:

- The 1 pixel border of the image which has insufficient data for the 3×3 convolution matrix. -> I choose to fill this with neutral 0x8080 values.
- The center area (width-2)*(height-2) should be filled with the new 14×14 routine.
- And finally there is a region on the right that is under 14 pixels of width and also on the bottom. The right side will be filled with a 14×14 routine. The bottom side will be filled with reduced height 14xN sse routines. (This will set the minimal input image size to 16×3).
For this I need a function which works on one horizontal ‘run’. I also introduce an ycount value, so the unique height of the last run can be specified:
void SSE_sobelRun(ubyte* src, uint* dst, size_t stride, size_t xcnt, size_t ycnt){ asm{
mov R10, src; mov R11, dst;
mov RDX, stride; shl RDX, 2; //this is the dst stride which is 4x bigger because ubyte->uint
pxor XMM8, XMM8; //const 0
pcmpeqb XMM9, XMM9; //const -1
mov R9, xcnt;
l0:
mov RAX, R10; mov RDI, R11;
movaps XMM0,XMM1; movaps XMM1,XMM2; movups XMM3,[RAX]; add RAX, stride; movaps XMM13,XMM14; movaps XMM14,XMM15; movaps XMM15,XMM3; movaps XMM2,XMM3; movaps XMM4,XMM3; pslldq XMM2,1; psrldq XMM4,1; pavgb XMM2,XMM4; pavgb XMM2,XMM3;
movaps XMM0,XMM1; movaps XMM1,XMM2; movups XMM3,[RAX]; add RAX, stride; movaps XMM13,XMM14; movaps XMM14,XMM15; movaps XMM15,XMM3; movaps XMM2,XMM3; movaps XMM4,XMM3; pslldq XMM2,1; psrldq XMM4,1; pavgb XMM2,XMM4; pavgb XMM2,XMM3;
mov R8, ycnt;
l1:
movaps XMM0,XMM1; movaps XMM1,XMM2; movups XMM3,[RAX]; add RAX, stride; movaps XMM13,XMM14; movaps XMM14,XMM15; movaps XMM15,XMM3; movaps XMM2,XMM3; movaps XMM4,XMM3; pslldq XMM2,1; psrldq XMM4,1; pavgb XMM2,XMM4; pavgb XMM2,XMM3;
//here we have 3 GY rows in XMM0..XMM1
movaps XMM3,XMM2; movaps XMM4,XMM0; pxor XMM4, XMM9; pavgb XMM3,XMM4; //XMM3: GY
movaps XMM4, XMM13; pavgb XMM4, XMM15; pavgb XMM4,XMM14; //XMM4: vertical convolution with [1,2,1]
movaps XMM5, XMM4; pslldq XMM4,1; psrldq XMM5,1; //XMM4, XMM5: left/right neighbors
pxor XMM4, XMM9; pavgb XMM4,XMM5; //XMM4: GX
//pack RGBA(GX,GY,Luma,0)
psrldq XMM4,1; psrldq XMM3,1; movaps XMM5,XMM14; psrldq XMM5,1; movaps XMM6,XMM4; punpcklbw XMM4,XMM3; movaps XMM7,XMM6; punpckhbw XMM6,XMM3; movaps XMM0,XMM5; punpcklbw XMM5,XMM8; punpckhbw XMM0,XMM8; movaps XMM10,XMM4;
punpcklwd XMM4,XMM5; add RDI, RDX; punpckhwd XMM10,XMM5; movups [RDI+0x04],XMM4; movaps XMM5,XMM6; movups [RDI+0x14],XMM10; punpcklwd XMM6,XMM0; movups [RDI+0x24],XMM6; punpckhwd XMM5,XMM0; movq [RDI+0x34], XMM5;
dec R8; jnz l1;
add R10, 14; add R11, 14*4; //advance next block to the right
dec R9; jnz l0;
}}
The above code can transform an area where height = ycnt+2; and width = 2+xcnt*14;
The following code will utilize this sse function to transform a arbitrary sized image. It also keeps the blockHeight at 14 pixels for better cache locality.
void SSE_sobel(Image!ubyte src, Image!uint dst, bool main){
enum BW = 14, //blockWidth
BH = BW, //blockHeight
def = 0x8080; //default color
dst.size = src.size;
int w = src.width,
wBH = w*BH,
h = src.height;
if(w<=BW+2 || h<3) { sobel(src, dst); return; } //revert to slow algo
int xBlocks = (w-2)/BW,
yBlocks = (h-2)/BH,
xRemaining = w-2-xBlocks*BW,
yRemaining = h-2-yBlocks*BH,
xLastIdx = xRemaining ? w-16 : 0;
dst.data[0..w] = def; //first default line
void doRun(int y, int yCnt=BH){
int ofs = y*wBH;
foreach(i; 1..yCnt+1) dst.data[ofs+i*w] = def; //left side
SSE_sobelRun(&src.data[ofs], &dst.data[ofs], w, xBlocks, yCnt); //blocks
if(xLastIdx) SSE_sobelRun(&src.data[ofs+xLastIdx], &dst.data[ofs+xLastIdx], w, 1, yCnt); //last block
ofs += w-1; foreach(i; 1..yCnt+1) dst.data[ofs+i*w] = def; //right side
}
foreach(y; 0..yBlocks) doRun(y);
if(yRemaining>0) doRun(yBlocks, yRemaining);
dst.data[$-w..$] = def; //last default line
}
And before the benchmark results, here is the original D sobel function:
void sobel(Image!ubyte iSrc, Image!uint iDst){ //input: 8bit luminance Output:32bit (GX, GY, Luma, 0)
iDst.size = iSrc.size;
const w = iSrc.width,
h = iSrc.height;
auto src = iSrc.data;
auto dst = iDst.data, dst2 = dst;
enum def = 0x8080;
if(w<3 || h<3){ dst[0..w*h] = def; return; } //too small
int w2 = w*2;
dst[0..w] = def; //clear first line
dst = dst[w..$]; //go to next line
foreach(int y; 1..h-1){
int d0 = y*w;
dst[0] = 0;//first pix
foreach(int x; 0..w-2){
int smp(int ofs){ return cast(int)src[ofs+x]; }
int gx =( 1*smp(0 ) +2*smp( w ) +1*smp( w2)
-1*smp(2 ) -2*smp(2+w ) -1*smp(2+w2) )>>3;
int gy =( 1*smp(0 ) +2*smp(1 ) +1*smp(2 )
-1*smp(0+w2) -2*smp(1+w2) -1*smp(2+w2) )>>3;
uint i2u(int a){ return (a+128); }
dst[x+1] =(i2u(gx) )|
(i2u(gy) <<8)|
(smp(w+1) <<16);
}
dst[w-1] = def;//last pix
dst = dst[w..$]; src = src[w..$]; //advance
}
dst[0..w] = def; //last line
}
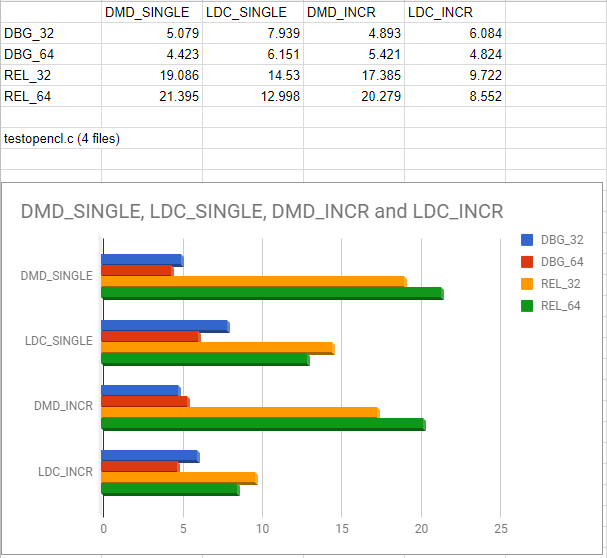
Benchmark results
Test image size: 1600*1200
System: CPU: AMD FX-8350, 4.1GHz, Ram: 2133MHz Dual Ch, Win10 64bit
Compiler: LDC – the LLVM D compiler (1.6.0)
Compiler options: ldmd2 – m64 – mcpu=athlon64-sse3 -mattr=+sse3 -release -O -inline -boundscheck=off
Results: 10.2ms vs 2.5ms That’s 4.1x speedup for the first test ever.
Let’s tune it up!
There are 2 things on my mind: cache handling and choosing the ideal blockheight.
Cache handling: From now I use the prefetcht0 instruction in the row_fetch code:
movaps XMM0,XMM1; movaps XMM1,XMM2; movups XMM3,[RAX]; add RAX, stride; movaps XMM13,XMM14; movaps XMM14,XMM15; prefetcht0 [RAX]; movaps XMM15,XMM3; movaps XMM2,XMM3; movaps XMM4,XMM3; pslldq XMM2,1; psrldq XMM4,1; pavgb XMM2,XMM4; pavgb XMM2,XMM3;
For the memory writing operations I’m unable to skip the cache because movntps needs to be aligned to 16bytes. Out algorithm can only guarantee 4 byte align.
Interestingly with the 1600 pixels wide image it turned out that blockHeigh=2 is the best height. This way the algorithm reads a 1600*(1+2+1) area and writes a 1600*2*4 area in one ‘run’. So I’ve upgraded the blockHeight calculation like this:
BH = (4096/src.width).clamp(2, BW)
Final results: 10.2ms vs 2.2ms speedup: 4.6x
There are still some minor improvements in my mind but those aren’t worth the time. For example: Currentle the 2 input rows and the 3 [1,2,1] premultiplied rows are stored in a queue in XMM0..XMM2 and XMM14..XMM15. Some move instructions could be eliminated if those would be true circular buffers. But that would make the code 3x bigger and 10x nastier. Probably wouldn’t worth the effort.
Checking the code generated by LDC2

No signs of auto-vectorization here. The math is done by mainly LEA, SUB, SAR.
Conclusion
Although when I work with SSE byte[16] data I always expect 16x speedup, with this algorithm I only achieved 4.6x. For the first try it’s ok. I’d give 3 out of 5 stars…